






こんにちは。スプラシアのSREに所属している井上です。
弊社のインフラは主にAWSを利用しているのですが、毎月増えていく利用料金は悩みのタネの一つでもあります。
そこで、今回は私たちがコスト最適化にあたって気を付けていることや、導入しているものを紹介したいと思います。基本のキなことが多いですが、どなたかの参考になれば幸いです。
1.リソースにはProjectタグを付与する
何の案件に使用されていて、どのくらい料金が発生しているのかを管理したく、リソースには
「タグキー:Project=バリュー:案件名」
というようにタグをつけることを忘れないようにしています。
とはいえ忘れることもあるので、時間があるときにResorce GroupsのTag EditorやAWS Configの非準拠リソースを確認し、漏れが無いように気を付けています。ゆくゆくはアラートメールを飛ばすような実装もできればなと考えています。
ちなみに管理が難しい下記リソースにはProjectタグを付与していません。
・EC2 リザーブドインスタンス
・RDS リザーブドインスタンス
・GuardDuty
これらのリソースは、Cost Explorerの「タグキーがありません:Project」として管理しています。
こちらには税金も含まれるのですが、Projectタグをつけ忘れてしまったリソースの費用も含まれるので、毎月一喜一憂しています。
「タグキーがありません:Project」の費用=各リザーブドインスタンスの費用+SavingsPlansの費用+GuardDuty+税金 までにするのは難しいのですが、近づけるように努力しています。
タグ付けは初歩的なことではありますが、大事ですね。
2.Cost Explorerを確認する
毎月発行される請求書やCost Explorerを定期的に確認します。
何にお金がかかっているのか?本当に必要な費用なのか?を把握するためです。
弊社ではRDSやEC2等のサービス毎の費用と、
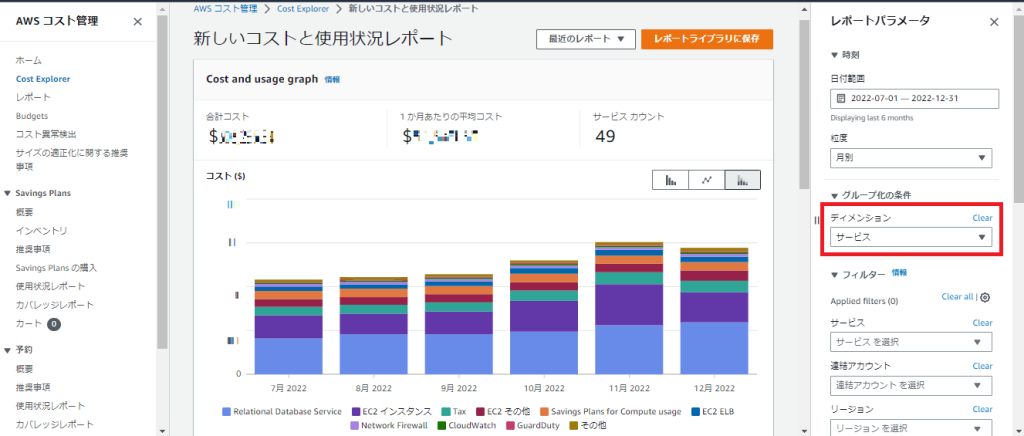
赤枠部分のディメンションで「サービス」を指定。
RDSの使用量が多いことが分かります。
Projectタグ別に費用をそれぞれcsvファイルで出力し、毎月の初めに増減量などを確認しています。
(前述したProjectタグは主にここで確認するために付与しています。)
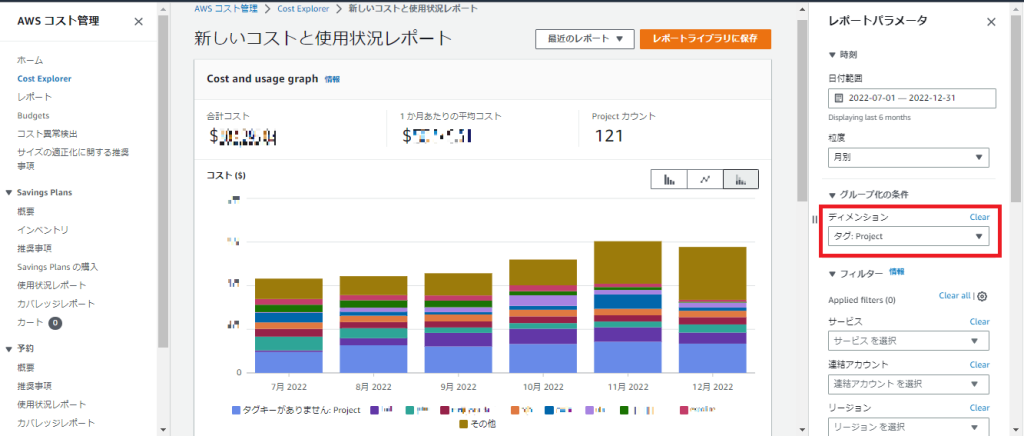
赤枠部分のディメンションで「タグ:Project」を指定。
「タグキーがありません:Project」が多いですね。
サービス毎の費用を確認しながら気づけたのは不要なCloudWatchのダッシュボードの削除漏れでした。
負荷テストツールとしてDistributed Load Testing on AWSを使用することが多いのですが、それを使用するとダッシュボードが自動生成されることを知らず、不要な数ヵ月分の費用が徴収されていたことに気づいた時は悲しくなりました…。ダッシュボードは1つあたり3ドルもかかってしまうので、これからも消し忘れには気を付けたいです。
3.不要なリソースを洗い出す
一時的に取得したスナップショットやAMI、もう不要なRoute53のホストゾーンなどが無いか定期的に確認します。
私の中で消し忘れが発生しやすい以下は、特に気を付けています。
(箇条書きにして気付きましたが、結構ありますね…。)
・EC2やRDSの手動スナップショット
・AMI
・使用可能になっているボリューム
・何にもアタッチされていないElastic IP
・Route53の未使用ホストゾーン
・Cloudwatchのダッシュボード
また、頻繁には行いませんが、使用している全リソースを洗い出してSREメンバーで不要か必要かを慎重に確認して削除します。
(全てのリソースを手動で洗い出すのは非常に面倒なので、AWS CLIで一括で出力できるようにコマンドを使用しています。こちらは機会があれば別記事でご紹介したいと思います。)
他にも稼働中のEC2インスタンスやRDSの中で、スペックが下げられそうなリソースは社内の担当者と相談し、日程を調節してスペックを下げる、もしくは削除することもあります。
EC2インスタンスに関してはComputeOptimizerの検出結果も1つの基準としています。

ComputeOptimizerで検知された「CPUが過剰なプロビジョニング」のEC2インスタンスたち
4.リザーブドインスタンス、SavingsPlansを活用する
CostExplorerのカバレッジレポートを参考にリザーブドインスタンスやSavingsPlansを購入しています。

リザーブドインスタンスのカバレッジレポート。
「平均カバレッジ」が0%に近いほど、削減の余地ありです。
一例にはなりますが、導入の判断基準は下記のようにしています。
・1年以上稼働しそうなEC2インスタンス&RDS ⇒ リザーブドインスタンス
・上記以外のEC2インスタンスで使用頻度の高いインスタンスファミリー(t3系など) ⇒ EC2 Instance Savings Plans
SavingsPlansの料金は、請求ダッシュボード>CostExplorer>SavingsPlansの推奨事項を参考にし、チーム内で話し合って決めています。
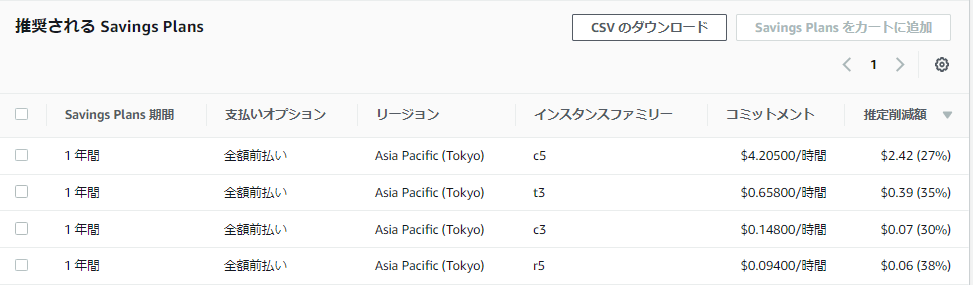
EC2 Instance Savings Plansの推奨事項
数年前まで、このような削減案は管理が難しそうなイメージがあり、最低限の導入しかしていませんでした…。
思い切って導入してみたところ想定よりも使いやすく、オンデマンドで使用するよりも30%近い費用が削減できています。もっと早くやれば良かったと後悔しています。
SavingsPlansにはEC2 Instance Savings Plansの他にも、LambdaやFargateなどが節約できるCompute Savings Plansもあるので、調べながら上手く活用していきたいです。
番外編.これから導入してみたいこと
多くのアクセスが予想されるサーバーは冗長化を行っていますが、負荷テストの結果を基準に台数を決めることが多く、こんなに必要なのかな?と思うことが正直あります。
EC2 Auto Scalingを使用することで無駄なサーバーの稼働が減らせると思うので、メリットデメリットを考慮して導入していけたらと考えています。
また、オンデマンドのEC2インスタンスだけではなく、スポットインスタンスもうまく活用できるようになりたいです。
あとは東京リージョンのサーバー費用が他リージョンに比べて少々お高めなので、うまくリージョンを使い分けていけることが理想だな~と思っています。
まとめ
自戒も込めてこの記事を作成しましたが、気を抜くと無駄なリソースがどんどん増えてしまうので改めて気を付けなければと思いました。
削減案は上記以外にもたくさんあるので、もっとAWSに詳しくなって今よりも削減できるようになりたいです!
関連カテゴリ 最新記事一覧





- CATEGORY
- TAG
-
- NEW TOPICS